Vision-Language-Action (VLA) models are increasingly expected to not only complete robot tasks,
but also follow human instructions about how those tasks should be executed. However, existing
robot datasets usually pair trajectories with coarse goal-level language, leaving execution-critical
details such as active arm, approach direction, and contact region unspecified. This limits steerable
policy learning and robotic video understanding.
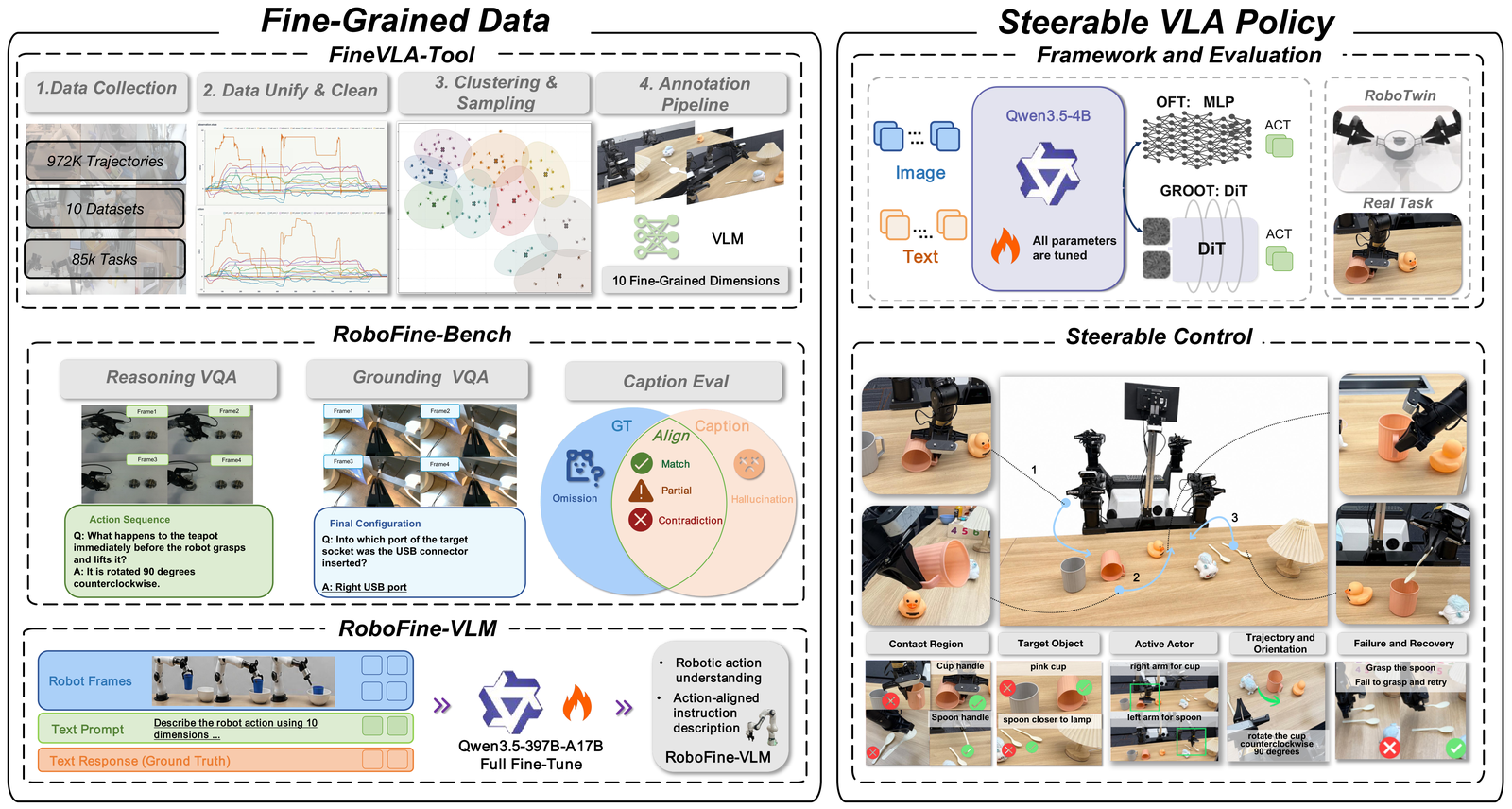
We introduce FineVLA, an open framework for action-aligned fine-grained VLA supervision.
The framework includes:
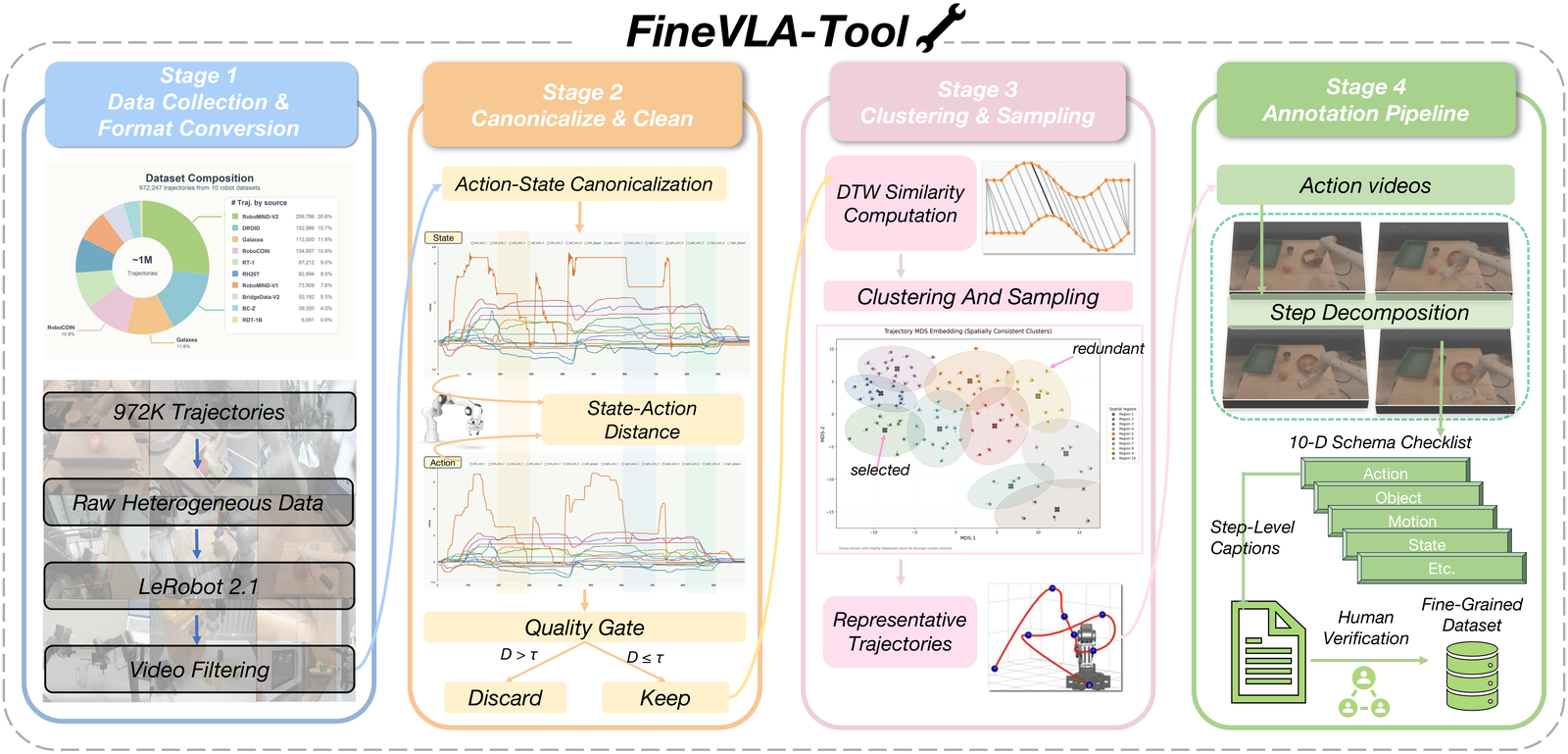
(1) a data construction tool that unifies 972,247 trajectories across 85K tasks from 10 open-source
robot datasets and builds FineVLA-Data, a human-verified dataset of 47,159 fine-grained trajectories;
(2) a held-out benchmark with 500 videos, 11,631 atomic facts, and 1,030 VQA questions;
(3) a robotics-specialized VLM annotator for scalable fine-grained annotation; and
(4) a steerable VLA policy trained with controlled mixtures of fine-grained and raw goal-level instructions.
Our policy experiments yield three findings. First, fine-grained supervision does not sacrifice
goal-level task success: FG-only improves over Raw-only by +1.4 to +8.1 success-rate points.
Second, fine-grained and raw instructions are complementary: performance follows a consistent
inverted-U trend, peaking around FG:Raw = 1:2 to 1:1. The strongest mixed setting reaches
86.8%/82.5% in RoboTwin simulation and 62.7/100 in real-world
dual-arm manipulation, compared with 49.9 for Raw-only. Third, fine-grained supervision directly
improves steerable control: in real-world evaluation, the largest gains over Raw-only appear on
pose (+23), color (+18), and approach direction (+18)—factors where goal-level instructions
provide no guidance.
 XLANG Lab, The University of Hong Kong,
2
XLANG Lab, The University of Hong Kong,
2 Qwen Team, Alibaba Inc.
Qwen Team, Alibaba Inc.